



Decommission & Cleanup Legacy S3 Buckets at Scale

Table of Contents
- Introduction
- Ensure Nobody is Using the Buckets
- Block All Bucket Access
- Checks Before Cleanup
- Confirm Nobody Accessed the Buckets Recently
- Empty S3 Buckets Using Lifecycle Policies
- Conclusion
Introduction
As part of a multi-year large-scale restructuring of our 90+ AWS accounts, we recently migrated a lot of workloads from legacy accounts to new ones. These workloads left behind thousands of S3 buckets with terabytes of data across several accounts & regions. After migrating all relevant data, we embarked on a journey of systematically cleaning up our S3 footprint. This article is the story of how we achieved this.
The entire journey can be summarized into two big steps:
- First, ensure nobody is using the S3 buckets
- Second, delete all data & buckets in S3
Although these might seem trivial, it gets really complicated at the scale of thousands of buckets with terabytes of data across billions of objects. You’ll need to build some kind of automation at every step, otherwise the scale of the task at hand is truly overwhelming.
Ensure Nobody is Using the Buckets
To ensure nobody was using the buckets, we took the following steps:
- Block all access to all buckets from everywhere except from a special “admin” role, not used by any workloads or users (except us)
- Enable S3 bucket access logging on all buckets
- Wait a few weeks & see if anyone complains about broken workloads or being unable to access some buckets
- If you operate at a big enough scale, there’s almost always someone who complains when you block access
- In our case, even though the workload migration away from these buckets had begun over two years ago, we still had a team complain about failing ETL jobs, thus holding up our cleanup of over 10 terabytes of data
- After waiting a few weeks & resolving all complaints, we could finally begin the cleanup
Block All Bucket Access
The simplest way to block all access to a bucket is using a bucket policy. Remember to include an exception to the deny policy, or you’ll end up locking yourself out of the bucket.
By the way, if you do end up locking yourself out of a bucket, here is some great guidance from AWS on how to regain access:
I accidentally denied everyone access to my Amazon S3 bucket. How do I regain access?
Here is the bucket policy you can use to block access:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::BUCKET_NAME",
"arn:aws:s3:::BUCKET_NAME/*"
],
"Condition": {
"ForAllValues:ArnNotLike": {
"aws:PrincipalArn": "arn:aws:iam::ACCOUNT:role/ROLE_NAME"
}
}
}
]
}Checks Before Cleanup
Weeks later, when you’re ready to start deleting stuff, you might wanna do a few prerequisite checks beforehand. One such check would be ensuring that all buckets have the right bucket policies & access logging enabled. Here’s a simple script to do that:
#!/usr/bin/env bash
BUCKETS=$(aws s3api list-buckets \
--query 'Buckets[].Name' --output text)
for BUCKET in $BUCKETS; do
echo "$BUCKET"
aws s3api get-bucket-logging \
--bucket "$BUCKET" | cat
aws s3api get-bucket-policy --bucket \
"$BUCKET" --query Policy | jq -r | jq
doneThis script simply outputs the bucket name along with its access logging & bucket policy for all buckets:
BUCKET_NAME
{
"LoggingEnabled": {
"TargetBucket": "TARGET_BUCKET",
"TargetPrefix": "PREFIX/"
}
}
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::BUCKET_NAME",
"arn:aws:s3:::BUCKET_NAME/*"
],
"Condition": {
"ForAllValues:ArnNotLike": {
"aws:PrincipalArn": "arn:aws:iam::ACCOUNT:role/ROLE_NAME"
}
}
}
]
}Confirm Nobody Accessed the Buckets Recently
In some cases, there might be unattended workloads silently failing since you blocked S3 access. Just because nobody complained about them doesn’t mean you can ignore them. So how do you catch such cases? This is where the access logging comes in handy.
Using Athena, you can query S3 access logs & look for any failing access requests. But first, set up Athena to query S3 logs as described below:
How do I analyze my Amazon S3 server access logs using Athena?
Once you have Athena set up, you can start querying the S3 logs looking for access attempts since you blocked S3 access. Here is an example Athena query:
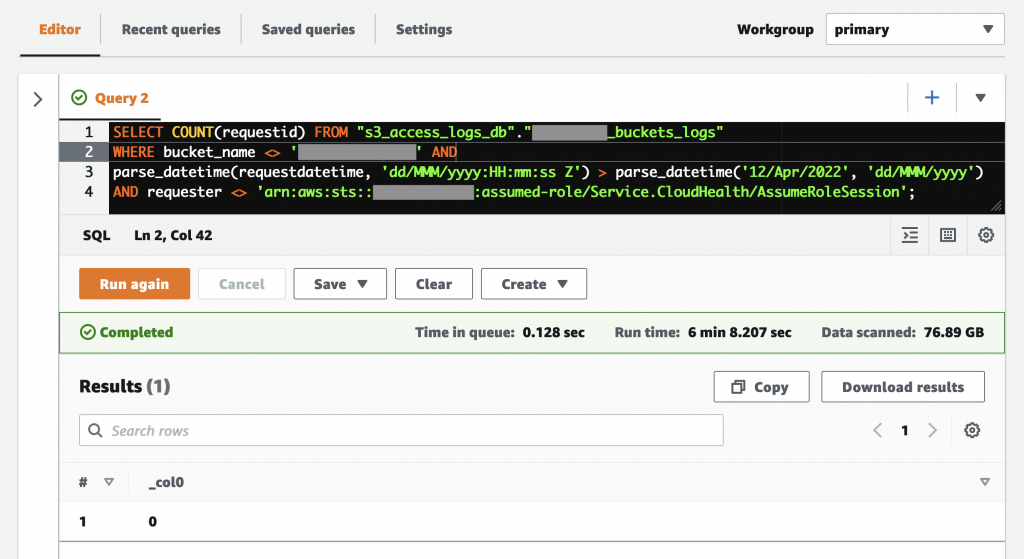
A few things to note about the above query (specific to our scenario):
- Line 2 excludes a particular bucket that we could not delete just yet since a workload was still using it
- Line 3 looks for events only after we blocked S3 access
- Line 4 filters out access attempts from expected sources, like CloudHealth in our case
Empty S3 Buckets Using Lifecycle Policies
As you might know, S3 buckets must be empty before they can be deleted. Deleting millions of objects from a bucket can be very time consuming. As such, it’s recommended to have an S3 lifecycle policy do the deletion for you.
You will however, need a script to create the lifecycle policies on all your buckets, just as with the bucket policies & access logging. Here’s the script we used:
#!/usr/bin/env python3
import boto3
s3 = boto3.resource('s3')
for b in boto3.client('s3').list_buckets()['Buckets']:
bucket = b['Name']
print(bucket)
if bucket in ('BUCKET_TO_SKIP_1',
'BUCKET_TO_SKIP_2',
'BUCKET_TO_SKIP_3'):
print('Skipping...')
continue
s3.BucketLifecycleConfiguration(bucket).put(
LifecycleConfiguration={
'Rules': [{
'Expiration': {
'Days': 1,
},
'ID': 'empty-bucket',
'Prefix': '', # all objects
'Status': 'Enabled',
'NoncurrentVersionExpiration': {
'NoncurrentDays': 1
},
'AbortIncompleteMultipartUpload': {
'DaysAfterInitiation': 1
}
}]
}
)This lifecycle config will start deleting objects older than a day. You can leave this applied on your buckets for a day or so & then go in & finally delete the buckets themselves.
Conclusion
This article walked you through the cleanup of S3 buckets at scale, along with the precautions you should take to avoid breaking workloads. I hope this helps you the next time you encounter such a use case. ?