Welcome to the second part of our blog series, “Unlocking Document Processing at Scale with Amazon Textract.” In our previous installment, we explored the significance of documents in various industries, identified the challenges associated with manual document processing, and introduced Amazon Textract as a powerful solution for automating the extraction of structured data from documents. We also shed light on the diverse array of Amazon Textract APIs and provided insights into pricing considerations.
In this second part, we will embark on a practical journey. We’ll delve into the creation of a robust reference architecture that leverages Amazon Textract’s capabilities to establish a highly efficient, scalable, and serverless document processing solution. This architecture aims to streamline the way organizations handle documents, ensuring data accuracy, reducing manual effort, and enhancing productivity. Throughout this part of the blog series, I’ll guide you through each step of building this document-processing architecture, offering practical insights, tips, and best practices. By the end of this journey, you’ll be well-equipped to implement a document processing solution using Amazon Textract that aligns perfectly with your organization’s requirements and objectives.
So, let’s dive right in and explore the building blocks of this powerful reference architecture. It’s time to unlock the full potential of Amazon Textract for your document processing needs.
Prerequisites
To embark on our journey of building a robust document processing architecture with Amazon Textract, there are several prerequisites you should have in place. These prerequisites will help ensure a smooth and successful implementation of the architecture. Before diving in, please ensure that you meet the following requirements:
AWS Console Access: You must have access to the AWS Management Console. This is essential for configuring AWS services, creating resources, and monitoring the architecture we’ll be building.
Node.js, Python, and AWS CLI: Implementing our architecture involves coding in Node.js and Python. Therefore, it’s essential to have Node.js and Python installed on your system. Additionally, you should have the AWS Command Line Interface (CLI) installed and configured to interact with AWS services via the command line.
Familiarity with AWS CDK: We’ll use the AWS Cloud Development Kit (CDK) to provision and manage AWS resources. Prior knowledge of AWS CDK is beneficial.
Python and TypeScript Knowledge: As we work with both Python and TypeScript in this implementation, a fundamental understanding of these programming languages will be helpful.
CloudFormation and Serverless Services Familiarity: It’s beneficial to have some familiarity with AWS CloudFormation, as our architecture is defined using this service. Knowledge of AWS serverless services, such as AWS Lambda and Amazon DynamoDB is also advantageous.
Now that we’ve covered the prerequisites, let’s move forward and start building our Amazon Textract-based document processing architecture.
Document Processing Workflow with Amazon Textract
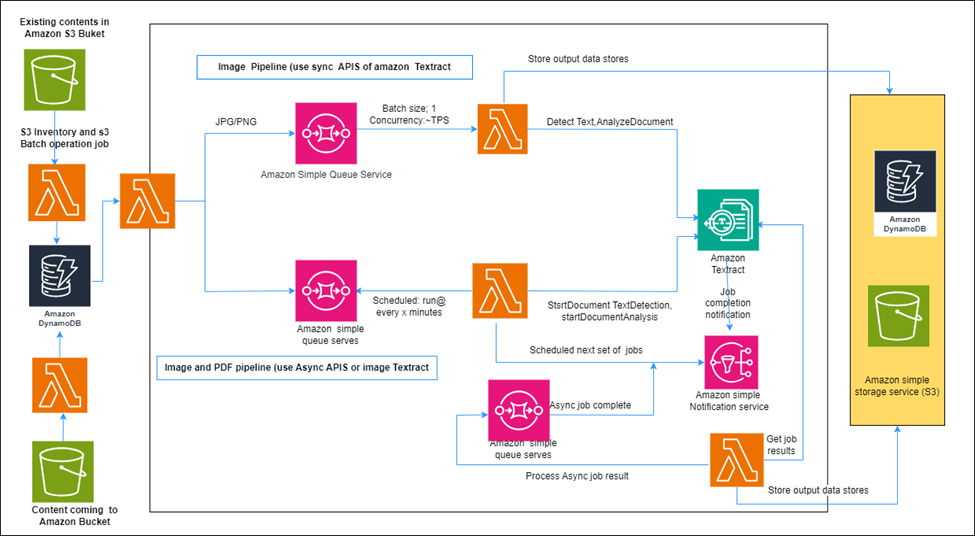
In our quest to build a robust document processing architecture using Amazon Textract, it’s essential to understand the workflow and pipelines that will enable us to process incoming documents efficiently. This workflow is designed to harness the full potential of Amazon Textract’s capabilities and ensure seamless document processing. We’ve outlined two distinct pipelines tailored to different document processing scenarios:
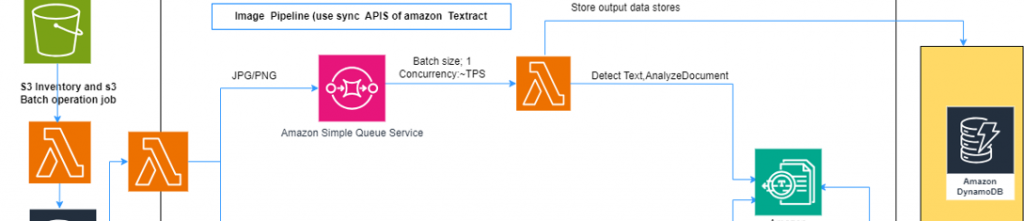
1. Image Pipeline (Using Sync APIs of Amazon Textract):
The image pipeline is ideal for processing small batches of images or PDFs synchronously. This scenario is commonly employed when a user uploads a document to a web application, and immediate processing and response are required.
Here’s how it works:
Document Submission: When a document is received, it is sent to an Amazon S3 bucket, where it is securely stored.
Lambda Function Activation: A Lambda function is triggered upon document arrival in the S3 bucket. This Lambda function reads the document from S3, preparing it for processing.
Textract Processing: The prepared document is then sent to Amazon Textract for processing. Textract, leveraging its powerful OCR capabilities, extracts text, forms, and tables from the document.
Result Storage: Once Textract has completed processing the document, the Lambda function retrieves the results and stores them in a database like Amazon DynamoDB. This ensures that the processed data is safely archived and can be easily accessed for further analysis.
The image pipeline is well-suited for scenarios where users interact with a web application and need immediate document processing, such as when uploading personal documents, invoices, or small document batches.
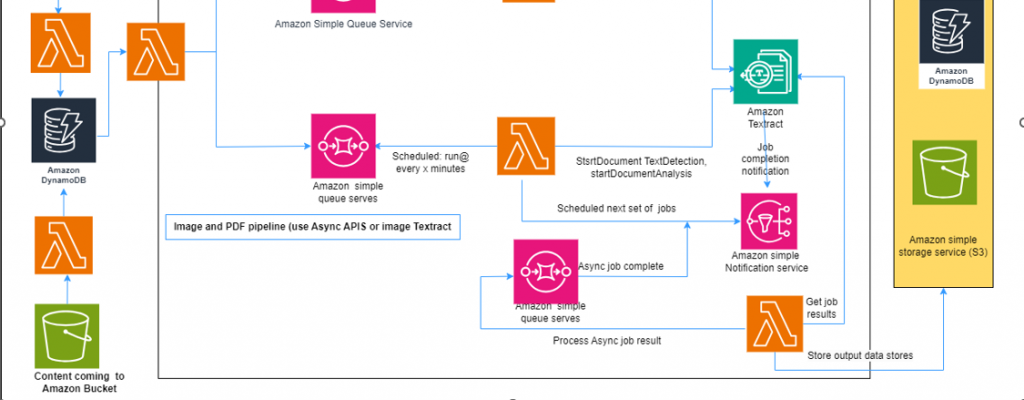
2. Image and PDF Pipeline (Using Async APIs of Amazon Textract):
In contrast, the image and PDF pipeline is designed to process large batches of images or PDFs asynchronously. This asynchronous approach is particularly beneficial when dealing with a significant volume of documents that don’t require real-time processing.
Here’s how this pipeline operates:
Document Submission: When a document is received, its metadata (like document name, and s3 Uri) is directed to an Amazon Simple Queue Service (SQS) queue. The queue acts as a buffer for incoming documents, allowing for efficient and orderly processing.
Lambda Queue Monitoring: A Lambda function monitors the SQS queue, periodically checking for new messages indicating the presence of documents. When a new message is detected, the Lambda function retrieves the document from the queue, preparing it for processing.
Textract Processing: The Lambda function then sends the document to Amazon Textract for processing, utilizing the service’s advanced OCR and machine learning capabilities.
Notification via SNS: Upon completion of document processing, Textract publishes a notification to an Amazon Simple Notification Service (SNS) topic, signaling that the document processing is finished.
Lambda Result Retrieval: Another Lambda function, subscribed to the SNS topic, is triggered when a notification is published. This Lambda function retrieves the results from Textract.
Result Storage: Just as in the image pipeline, the retrieved results are stored in a database, such as Amazon DynamoDB, making them easily accessible for further analysis and reporting.
The image and PDF pipeline is particularly useful when you have a large backlog of documents that need to be processed. By leveraging the asynchronous approach, you can avoid overwhelming Amazon Textract and prevent performance issues.
Overview of Source Code and Components
In this section, we’ll provide a brief introduction to the key components and Lambda functions within the source code. Each Lambda function serves a specific role in document processing and automation.
TextractPipelineStack:
Purpose: This TypeScript code is part of the AWS Cloud Development Kit (CDK) and defines the infrastructure for document processing. Functionality: It sets up the necessary infrastructure for building a document processing pipeline using AWS CDK. This includes IAM roles, Lambda functions, SQS queues, and more. The infrastructure enables document ingestion, processing, and PDF generation, integrating Textract services for document analysis. Lambda functions are associated with layers for code reuse, and they have the required permissions and triggers.
s3batchLambda:
Purpose: This Lambda function handles events generated by S3 Batch operation jobs. Functionality: It processes objects stored in an S3 bucket, identifies valid document types (images or PDFs), and stores relevant information in a data store. It responds with success or failure information.
s3EventProc: Purpose: This Lambda function is designed to respond to S3 object creation events. Functionality: Triggered by S3 events, it processes and stores documents in tables specified via environment variables when valid document types are uploaded to the S3 bucket. It automates document processing tasks upon object addition.
SourceS3BKT: The source S3 bucket serves as the primary storage repository for both synchronous (sync) and asynchronous (async) document processing. Documents are initially stored in this central location, from where they are automatically routed to their respective processing pipelines, ensuring a streamlined and efficient document processing workflow.
docProcLambda:
Purpose: This Lambda function is responsible for routing documents to either sync or async pipelines. Functionality: It categorizes documents into different SQS queues based on their file extensions. This function is designed to work with AWS Lambda and DynamoDB events, serving as part of a broader system for document processing and queuing.
syncSQSQueue: Specifically, these queues are used to transmit metadata and information about uploaded S3 objects or documents, enabling the orchestration of subsequent processing tasks by Lambda functions. They serve as a reliable means of inter-service communication, ensuring that data flows efficiently between components, ultimately contributing to the smooth operation of our document processing system.
syncProcLambda: Purpose: This Lambda function handles documents from a queue and processes them using sync APIs.
Functionality: Designed for serverless environments like AWS Lambda, it processes documents asynchronously as they are added to a queue. AWS Textract is used to analyze document content, and the processing results are updated in a DynamoDB table. It responds with a success status code (HTTP 200) and a message indicating successful processing.
SuccessSNSNotification:SNS enables the dissemination of messages and notifications to various parts of the system, keeping all services informed about critical events and updates. It plays a key role in orchestrating the flow of information, ensuring that relevant parties are promptly notified, and enabling efficient coordination among the different components of our document processing infrastructure.
asyncprocLambda: Purpose: This Lambda function processes documents from a queue and initiates async Amazon Textract jobs. Functionality: Triggered by events, such as S3 bucket notifications, it handles documents asynchronously using Amazon Textract. It manages rate limits and provisioned throughput exceeded scenarios.
jobresultsprocLambda: Purpose: This Lambda function processes results from completed Amazon Textract async jobs. Functionality: It handles the outcomes of Textract jobs, processes them, and stores persistent information in DynamoDB tables. This function offers a standardized approach to asynchronous Textract job processing and can be deployed as an AWS Lambda function for automation.
DynamoDBTable: In our project, DynamoDB serves as a vital data store for tracking and managing unique document IDs and their processing statuses. This is particularly important for maintaining a comprehensive record of documents as they move through the document processing pipeline
Deployment Steps of Document Processing Workflow
The deployment steps for the Document Processing Workflow using AWS CDK are as follows:
Download Repository: – Download the repository containing the AWS CDK code for the Document Processing Workflow to your local machine from the link Unlocking-Document-Processing-at-Scale-with-Amazon-Textract. Install AWS CDK:- Ensure that you have the AWS Cloud Development Kit (CDK) installed. You can install it globally using the following npm command: npm install -g aws-cdk Navigate to Project Folder: – Change your working directory to the `textract-pipeline` folder within the downloaded repository. Install Dependencies: – Install the project-specific dependencies by running the following command inside the `textract-pipeline` folder: npm install Bootstrap CDK Environment:– Bootstrap the AWS CDK environment to prepare it for deployment by running the following command: cdk bootstrap Deploy the Stack:– Deploy the AWS CDK stack, which creates and provisions the infrastructure for the Document Processing Workflow, by running the following command: cdk deploy These steps will set up and deploy the AWS infrastructure described in the CDK code, including IAM roles, Lambda functions, S3 buckets, DynamoDB tables, and SQS queues, as outlined in the provided TypeScript code. This will allow you to operationalize the document processing workflow in your AWS environment.
Modify source code and update deployed stack
To modify source code and update the deployed stack in the context of your CDK-based infrastructure for AWS Lambda functions, you can follow these steps:
– Make desired changes to the Lambda functions located in the `src` folder. Modify their code to implement the required functionality or updates.
– Shared code is added as Lambda layers. Any code shared among multiple Lambda functions should be placed in these layers to ensure code reuse.
– Update variables in the `test.py` file located at the top of the test script to match the resources created by your deployment. These variables might include endpoint URLs, queue names, or bucket names.
– Once you’ve made changes to the Lambda functions in the `src` folder, you should copy the updated Lambda function code to the appropriate folders.
– Run the following command to deploy the changes to your AWS infrastructure:
cdk deploy
This command will apply your modifications to the AWS resources defined in your CDK stack.
Produce and View CloudFormation Template (Optional): – If you need to review the CloudFormation template generated by your CDK application, you can run the following command:
cdk synth
This will generate and display the CloudFormation template for your stack.
Produce and Export CloudFormation Template (Optional):– If you need to export the CloudFormation template to a specific directory, you can use the `-o` option. For example:
cdk synth -o textractcf
This command generates the CloudFormation template and exports it to the specified directory (in this case, “textractcf”). By following these steps, you can make changes to your Lambda functions, update the deployed CDK stack, and ensure that your AWS infrastructure reflects the modified code and configuration. The CDK deployment process simplifies the management of your infrastructure as code, making it easier to iterate and update your application.
Delete stack
To delete a stack using the`cdk destroy`, you can follow these steps:
Navigate to the Project Directory
– Open your terminal or command prompt.
– Navigate to the directory where your CDK project is located.
– Use the `cdk destroy` command followed by the name of the stack you want to delete. For example:
cdk destroy MyStackName
– The command will prompt you to confirm the deletion of the resources associated with the stack. Confirm by typing “y” or “yes.”
– CDK will initiate the deletion of the AWS resources associated with the stack. This may take some time, depending on the complexity of your stack.
– Once the stack and its associated resources have been deleted, you will receive a confirmation message.
– You can verify that the stack and its resources have been deleted by checking your AWS Console or by using AWS CLI commands.
Keep in mind that deleting a stack will remove all associated AWS resources, so be cautious when using the `cdk destroy` command, especially in a production environment.
Cost Evolution
The provided code for creating an AWS infrastructure for document processing can incur costs in the following ways:
Resource Creation Costs:- Deploying this reference architecture creates various AWS resources, such as Amazon S3 buckets, DynamoDB tables, and Lambda functions. These resources may have associated costs based on their usage, storage, and other factors.
API Usage Costs:– When you analyze documents using the deployed infrastructure, it makes API calls to Amazon Textract for document analysis. These API calls have associated costs, and you will be billed based on the number of requests and the volume of documents processed.
To manage and control costs, it’s essential to monitor your AWS usage and consider the following steps:
– Use AWS Cost Explorer and Billing and Cost Management tools to track your AWS expenditure.
– Set up budget alerts to receive notifications when your spending exceeds predefined thresholds.
– Regularly review and optimize your AWS resources to ensure you’re not incurring unnecessary costs.
– Consider implementing lifecycle policies for S3 buckets to manage object retention and storage costs.
– When you’re done with the infrastructure, make sure to delete the entire CloudFormation stack using `cdk destroy` as mentioned in the code comment. This will remove all the created resources and stop incurring costs associated with them.
Conclusion
Throughout this blog, we introduced the prerequisites for implementing this architecture, including AWS Console access, Node.js, Python, AWS CLI, familiarity with AWS CDK, Python, and TypeScript knowledge, and a grasp of CloudFormation and serverless services.
This blog post was written by Afjal Ahamad, a data engineer at QloudX. Afjal has over 4 years of experience in IT, and he is passionate about using data to solve business problems. He is skilled in PySpark, Pandas, AWS Glue, AWS Data Wrangler, and other data-related tools and services. He is also a certified AWS Solution Architect and AWS Data Analytics – Specialty.
Qloudx takes your privacy and security seriously.
We use cookies to collect information about you.
We use this information:
1. to give you a better experience (functional)
2. to count the pages you visit (statistics)
3. to serve you relevant promotions (marketing)
Click “ACCEPT” to give us your consent to use cookies for all these purposes.
Read more about how we use cookies to collect personal data: Privacy Policy
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are as essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.










[…] Check out the second post in this series to learn how to build this document-processing architecture. […]