Building Scalable Data Pipelines with AWS Serverless Services – Part 2
Building Scalable Data Pipelines with AWS Serverless Services – Part 2
Introduction
Welcome back to the second installment of our series on ‘Building Scalable Data Pipelines with AWS Serverless Services.’ In Part 1, we laid the foundation by exploring the essential concepts and initial setup. Now, in Part 2, we dive deeper into the world of serverless architecture to uncover advanced strategies and techniques that will help you supercharge your data pipelines. Let’s continue our journey through AWS’s serverless ecosystem as we harness its power to build efficient and scalable data pipelines.
In this blog post, I will walk you through the steps of creating a fully automated data pipeline using AWS serverless services, from ingesting data at the Bronze Layer to performing advanced analytics with Athena.
Data Pipeline components
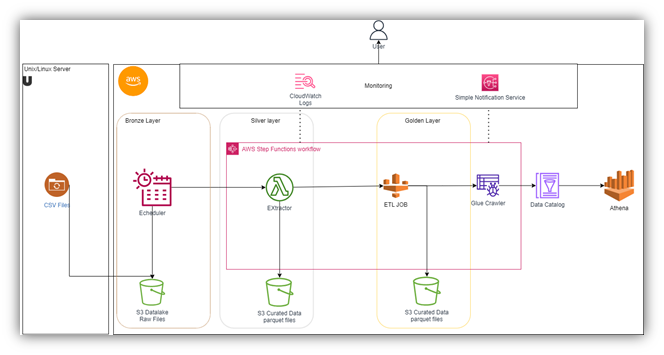
Ingesting Data at the Bronze Layer
Our data pipeline begins with ingesting raw data from an on-premises system into an S3 bucket named ‘src_bkt.’ This data is delivered in zipped compressed format daily via a cron job. This initial layer of data is referred to as the “Bronze Layer.”
Data Extraction and Transformation at the Silver Layer
Cleaning the data is essential to ensure that it is consistent and accurate, which will improve the quality of our analytics results. Inside the ‘DemoDataPipeLine’ state machine, we have a Lambda function named ‘extractor.’ This function is responsible for reading the zipped files from the source S3 bucket, decompressing them, and cleaning the data by removing null values. This processed data is now at the “Silver Layer.”
Further ETL Processing for the Golden Layer
In the Golden Layer, we perform additional transformations to prepare the data for analytics, such as aggregating the data and converting it to a common schema. After reaching the Silver Layer, the data goes through another ETL (Extract, Transform, and Load) job within the ‘DemoDataPipeLine’ state machine. This job performs additional transformations and cleaning to prepare the data for analytics. Once completed, the data is now in the “Golden Layer.”
Notifications with SNS
To keep the operations team informed about the progress of the data pipeline, we set up an AWS Simple Notification Service (SNS) topic. This topic sends notifications on every state transition within the ‘DemoDataPipeLine’ state machine, ensuring that the team is always up-to-date on the pipeline’s status.
Data Catalog and Table Population
A data catalog provides a central repository for metadata about datasets, making it easy to discover and manage data. With the data now in the Golden Layer, the ‘DemoDataPipeLine’ state machine triggers AWS Crawlers. These Crawlers automatically populate the data catalog with metadata about the datasets, making it easy to query and analyze the data.
Monitoring with CloudWatch
We are monitoring metrics such as Lambda execution time and error rate, as well as logs from our Lambda functions and ETL jobs. This allows us to quickly identify and resolve any issues that may arise. To ensure the reliability and performance of our data pipeline, we use AWS CloudWatch. CloudWatch provides monitoring and logging capabilities for our Lambda functions and ETL jobs, allowing us to track and troubleshoot any issues that may arise.
Scheduling Pipeline Execution with EventBridge
To automate the data pipeline, we utilize AWS EventBridge. We create an event rule named ‘pipeline-run-rule,’ which triggers our data pipeline, represented by an AWS Step Functions state machine called ‘DemoDataPipeLine,’ at a specific time daily. We are using EventBridge to schedule the pipeline to run once daily at midnight.
Data Analysis with Athena
Athena allows you to run SQL queries on the data catalog’s tables to perform a wide range of analytics, such as ad hoc analysis, reporting, and machine learning. Once the data catalog is populated, we can leverage AWS Athena for querying and analyzing the data. Athena allows you to run SQL queries on the data catalog’s tables, enabling data analysts and data scientists to gain valuable insights from the processed data.
Now, let’s dive deeper into the steps of building a data pipeline using AWS serverless services.
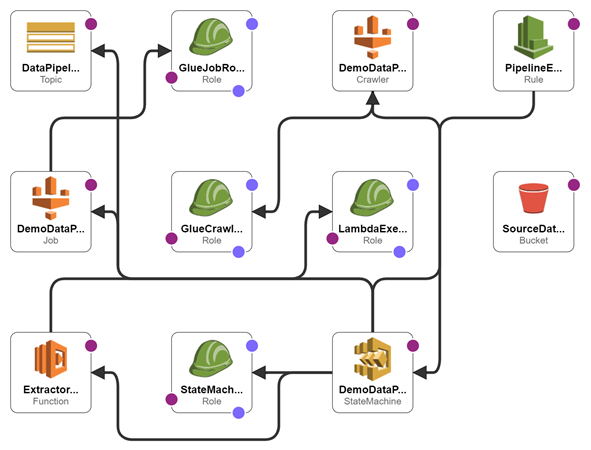
Figure I Architecture of the data pipeline we are going to build
Resource Deployment
Creating AWS resources using AWS CloudFormation is a great way to automate the provisioning and management of your infrastructure. Here’s an example CloudFormation script that creates the resources you described in your data pipeline.
You can find the CloudFormation template here at GitHub.
Note: Remember to review and adjust the IAM policies to provide the necessary permissions for your resources to interact with each other also change bucket and job names as per your resources.
Steps to Deploy Pipeline Resources
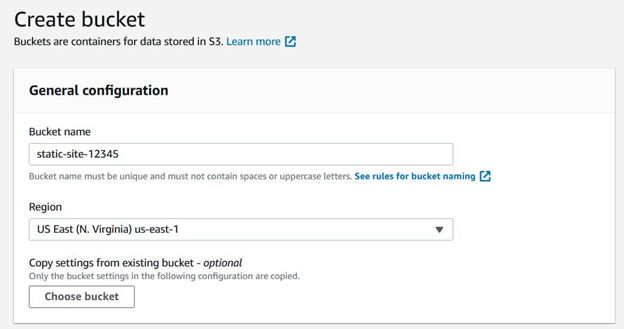
Create an S3 bucket with the appropriate Name.
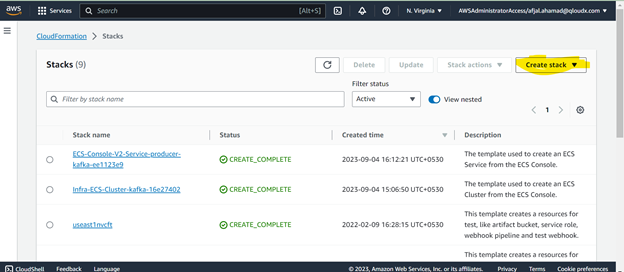
Go to Cloudformation Console and click on Create Stack.
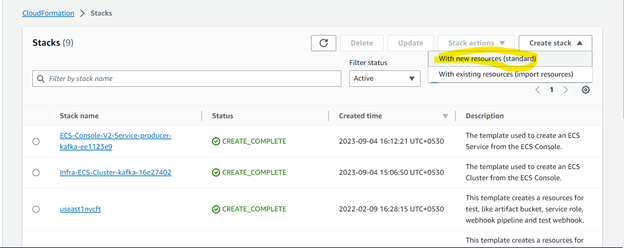
Click on Create with New Resources.
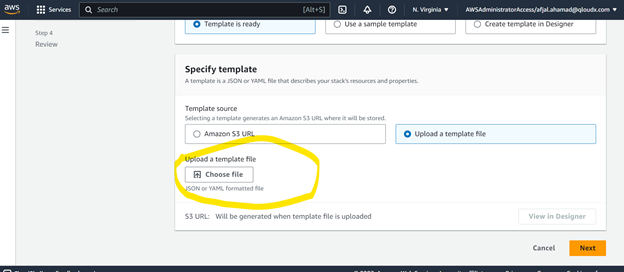
Upload Your CloudFormation Script YAML file.
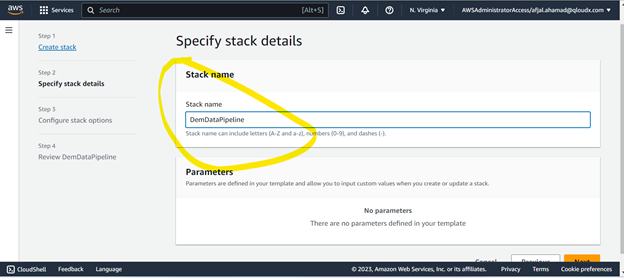
Provide the Name of your data Pipeline Stack.
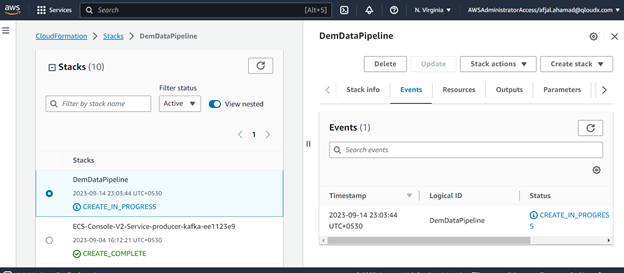
Monitor resource creation & events in the cloudformation console
This blog post describes the key steps to building a robust and fully automated data pipeline using AWS serverless services.
Figure II Cloudformation resource stack overview
Conclusion
AWS provides a comprehensive set of services that can be used to build data pipelines for a wide range of use cases, such as batch processing, stream processing, and machine learning. From ingesting data at the Bronze Layer to performing advanced analytics with Athena, AWS provides a comprehensive ecosystem of services to meet your data processing needs. By following these steps, you can create a reliable and scalable data pipeline that empowers your organization to make data-driven decisions confidently.
About the Author
This blog post was written by Afjal Ahamad, a data engineer at QloudX. Afjal has over 4 years of experience in IT, and he is passionate about using data to solve business problems. He is skilled in PySpark, Pandas, AWS Glue, AWS Data Wrangler, and other data-related tools and services. He is also a certified AWS Solution Architect and AWS Data Analytics – Specialty.
Qloudx takes your privacy and security seriously.
We use cookies to collect information about you.
We use this information:
1. to give you a better experience (functional)
2. to count the pages you visit (statistics)
3. to serve you relevant promotions (marketing)
Click “ACCEPT” to give us your consent to use cookies for all these purposes.
Read more about how we use cookies to collect personal data: Privacy Policy
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are as essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.