Data engineers play a pivotal role in the operations of modern data-centric enterprises. Their primary responsibility involves handling, transforming, and efficiently transmitting data to facilitate informed decision-making and generate valuable insights. But what exactly are the essential skills and fundamental concepts that empower data engineers to excel in their roles?
In this article, we will deep dive into the realm of data engineering, exploring the responsibilities of data engineers within data-driven organizations. Additionally, we will dissect the key proficiencies, principles, and tools that data engineers employ as part of their daily tasks.
The field of data engineering is experiencing rapid expansion, with a continuous surge in demand for individuals possessing these specialized skills. Whether you aspire to embark on a career as a data engineer or aim to enhance your existing skill set, this article serves as a valuable resource to guide you on your journey.
Let’s embark on this exploration together!
Responsibilities of a Data Engineer
The duties of a data engineer encompass, yet extend beyond, the following:
Gathering Raw Data: The collection of raw data from diverse sources for subsequent processing and storage in a data repository.
Infrastructure Selection: The evaluation and selection of the most suitable database, storage system, and cloud architecture or platform tailored to the specific project’s requirements.
System Design and Management: The creation, maintenance, and optimization of systems dedicated to data ingestion, processing, warehousing, and analysis.
Data Integrity and Security: The assurance that data remains highly available, secure, and compliant with the established standards within the organization.
Automation and Monitoring: The implementation of automated procedures and ongoing monitoring of data pipelines to guarantee the timely delivery of actionable insights.
Supporting Data-Driven Decision-Making: How Data Engineers Contribute
Data engineers play a pivotal role in facilitating data-driven decision-making by upholding the quality, accessibility, and reliability of data. The provision of inaccurate or subpar data by data engineers poses a risk to organizations, potentially leading to ill-informed decisions with significant consequences. To enable data scientists and analysts to effectively perform their duties, they necessitate access to top-tier, well-prepared data that has been meticulously processed by data engineers.
This data must adhere to an organization’s standardized structure and formatting, rendering it readily analyzable. By meticulously handling the laborious and time-intensive tasks related to data preparation and processing, data engineers empower both data scientists and analysts to focus on their core responsibilities.
Processes, Principles, and Competencies in Data Engineering
Now that we have a shared understanding of the responsibilities of data engineers, let’s delve into the essential skills, fundamental concepts, and indispensable tools that underpin their daily activities. Whether you aspire to embark on a career as a data engineer or are currently entrenched in the field, this discussion will provide valuable insights and serve as a beneficial refresher.
Three Essential Data Engineering Steps
In the world of data engineering, there are three core steps that data engineers use. If you’re thinking about pursuing a career in data engineering or already working in the field, understanding these steps is crucial.
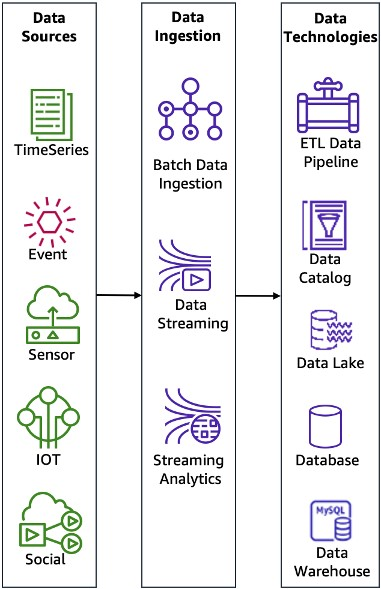
Step 1: Gathering Data
Imagine collecting data as picking up pieces from different places. This step is called data acquisition. It’s like moving data from one location to another. There are two main ways to do this:
Batch Data Ingestion: This means collecting and storing data at specific times, like on a schedule. It’s great for data that doesn’t need to be processed right away, like old data.
Example: Every night, an e-commerce website gathers sales data from all its stores and adds it to a database for later analysis.
Real-time Data Ingestion: This is like grabbing data as soon as it’s created. It’s used for data that needs to be processed right away, like streaming data. Gathering data can be tricky because data comes in many forms and from many sources.
Example: A ride-sharing app collects location data from drivers and riders in real time to calculate fares and provide ride recommendations.
Step 2: Preparing Data
Once you’ve gathered your data, it’s like having a bunch of puzzle pieces that don’t quite fit together. Data processing is focused on shaping those pieces to fit perfectly. Here’s how it’s done:
Data Cleaning: This is like finding and fixing mistakes in the puzzle pieces. It’s important to make sure your data is correct and reliable.
Example: Removing duplicate entries in a customer database to avoid sending the same promotional email twice.
Data Normalization: Think of this as making all your puzzle pieces the same size and shape. It’s about making your data consistent.
Example: Converting all currency values in a dataset to a common currency format (e.g., converting dollars to euros).
Data Reduction: Imagine throwing away any puzzle pieces that don’t help you solve the puzzle faster. Data reduction makes the analysis process quicker by removing unnecessary data.
Example: In a weather dataset, filtering out temperature records from sensors that are known to be inaccurate.
Data Extraction: It’s like taking specific puzzle pieces you need and putting them in a separate pile. This is often done when you need certain pieces for your analysis.
Example: Extracting sales data for a specific product category from a larger sales database.
Data Aggregation: Think of this as combining puzzle pieces from different sets into one big set. It’s important when you’re summarizing data from various sources.
Example: Combining sales data from multiple regions to create a total sales report for a company.
Step 3: Storing Data
Once your data is ready, you need to store it properly. Imagine putting your puzzle pieces in a container so that you can easily access and use them. Data storage is all about keeping your data in a format that’s easy for people and computers to work with. Here are some key points:
Structured Data: This is like neatly organizing your puzzle pieces. It’s easy for computers to understand and process. Think of databases like shelves to store this data.
Example: Storing customer information, such as names and addresses, in a structured database table.
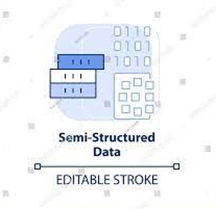
Semi-structured Data: These are like puzzle pieces in a bag. They have some order but are not as organized. Files like XML, JSON, or CSV are used for this kind of data.
Example: Saving email communication in JSON format, which includes sender, recipient, subject, and message body.
Unstructured Data: Think of this as a jumble of puzzle pieces. There’s no set order. It includes things like images, videos, and audio.
Example: Storing image files for facial recognition or video files for sentiment analysis.
Choosing where to store your data depends on factors like cost, performance, and reliability. There are various options, like relational databases (e.g., MySQL), NoSQL databases (e.g., MongoDB), and many tools & services provided by Cloud Providers etc.. Understanding these three steps is essential to mastering the art of managing data in the world of data engineering.
Data Engineering Key Concepts
Here are some important data engineering concepts that are essential Data Engineering.
Big Data: Big data refers to large and complex datasets that are challenging to process using traditional computing methods. It often includes massive volumes of data from various sources.
Business Intelligence (BI): Business intelligence involves processes and strategies for analyzing data to generate insights used for making informed business decisions.
Data Architecture: Data architecture encompasses the design, construction, and maintenance of data systems, including data models, databases, and data warehouses.
Containerization: Containerization is the packaging of applications so they can run in isolated environments called containers, improving resource utilization and portability.
Docker: Docker is a suite of tools used to create, run, and share containerized applications.
Kubernetes: Kubernetes (or k8s) is an open-source platform for managing containerized applications.
Cloud Computing: Cloud computing delivers IT services over the internet, and data engineers often use cloud-based services for data storage and processing.
Databases: Databases are collections of queryable data. Types include relational databases (e.g., MySQL), wide-column stores (e.g., Cassandra), key-value stores (e.g., DynamoDB), document databases (e.g., MongoDB), and graph databases (e.g., Neo4j).
Data Accessibility: Data accessibility is the ability of users to access data stored in a system.
Data Compliance and Privacy: Data compliance and privacy involve adhering to laws and regulations related to data protection and privacy.
Data Governance: Data governance is the management and regulation of data within an organization, including policies and procedures.
Data Integration Platforms: Data integration platforms help organizations combine data from multiple sources, often involving the processes of data cleaning and transformation.
Data Infrastructure Components: Data infrastructure components include virtual machines, cloud services, networking, storage, and software necessary for data systems to function.
Data Pipelines: Data pipelines automate the process of extracting data from sources, transforming it for downstream applications, and loading it into a target system.
Data Repositories: Data repositories or data stores are systems used to store data, including relational databases, NoSQL databases, and file systems.
Data Sources: Data sources are systems or devices from which data is extracted, including sources like U.S. Census data, IoT devices, and sensors.
Data Warehouses: Data warehouses are centralized systems for storing and managing collected data, often involving data extraction, transformation, and loading (ETL) processes.
Data Marts: Data marts are subsets of data warehouses containing data specific to a department or group.
Data Lakes: Data lakes store raw, unprocessed data from various sources, commonly used for data that hasn’t yet been transformed.
ETL and ELT Processes: ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes are used to move data between systems, with ETL focusing on data cleaning and ELT on transformation.
Data Visualization: Data visualization is the creation of visual representations to analyze data, find patterns, and aid decision-making.
Data Engineering Dashboards: Data engineering dashboards are web applications used to monitor data pipeline status and errors.
Data Formats: Data formats for storage include text files, CSV, JSON, XML, and binary formats like Parquet and Avro.
SQL and NoSQL Databases: SQL databases are relational databases suitable for structured data, while NoSQL databases handle unstructured and semi-structured data.
Technical Abilities and Tool Proficiency
Now that we’ve delved into the fundamental aspects of data engineering, let’s explore the array of tools and programming languages that data engineers employ to ensure the smooth operation of the data ecosystem.
Mastery of Operating Systems: Proficiency in Unix, Linux, and Windows, including a deep understanding of system utilities and commands.
Familiarity with Infrastructure Components: Knowledge of essential infrastructure elements such as virtual machines, networking, application services, and cloud-based services.
Expertise in Databases and Data Warehouses
Adeptness in managing databases and data warehouses, encompassing relational database management systems (RDBMS) like MySQL, PostgreSQL, IBM DB2, and Oracle Database.
Proficiency in NoSQL databases like Redis, MongoDB, Cassandra, and Neo4J.
Familiarity with data warehouses such as Oracle Exadata, Amazon RedShift, and IBM DB2 Warehouse on Cloud.
Understanding of Data Pipeline Technologies
Familiarity with popular data pipeline tools, including Apache Beam, AirFlow, and DataFlow.
Language Proficiency: Competence in various languages, including:
Query languages such as SQL.
Programming languages like Python and Java.
Shell and scripting languages, such as bash and sh.
Big data processing tools like Hadoop, Hive, Apache Spark, MapReduce, and Kafka.
Data Visualization Tools
Proficiency in utilizing data visualization tools like Tableau, QlikView, Power BI, and Microsoft Excel to present data effectively.
Version Control
Utilization of version control systems like Git, GitHub, and Bitbucket to manage code and collaborate with teams.
Continuous Integration and Continuous Delivery (CI/CD)
Familiarity with CI/CD practices and tools like Jenkins and Bamboo to automate software development and deployment processes.
Monitoring and Logging
Proficiency in monitoring and logging tools, including the ELK (Elasticsearch, Logstash, Kibana) stack, Splunk, and AppDynamics, to ensure the health and performance of the data ecosystem.
Conclusion
In conclusion, the role of a data engineer is multifaceted, encompassing the design, implementation, and maintenance of systems critical for the storage, processing, and analysis of data. Given the dynamic nature of the field, data engineering lacks a one-size-fits-all approach, making continuous learning and adaptation essential.
This blog post was written by Afjal Ahamad, a data engineer at QloudX. Afjal has over 4 years of experience in IT, and he is passionate about using data to solve business problems. He is skilled in PySpark, Pandas, AWS Glue, AWS Data Wrangler, and other data-related tools and services. He is also a certified AWS Solution Architect and AWS Data Analytics – Specialty.
Qloudx takes your privacy and security seriously.
We use cookies to collect information about you.
We use this information:
1. to give you a better experience (functional)
2. to count the pages you visit (statistics)
3. to serve you relevant promotions (marketing)
Click “ACCEPT” to give us your consent to use cookies for all these purposes.
Read more about how we use cookies to collect personal data: Privacy Policy
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are as essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.